

XGBoost - XGBoost
Links to Other Parts of Series
Prerequisites
Overview
If you’re not familiar with Decision Trees, Random Forests, AdaBoost, and / or Gradient Boost, and haven’t already checked out the blog posts linked above, please check that out first before proceeding with this post on XGBoost, since this does build upon the former posts.
Now that we got that covered, let’s dive right in!
What is XGBoost?
XGBoost stands for eXtreme Gradient Boosting, so it should be no surprise that it is somewhat rooted in Gradient Boosting, but just … brought to an extreme. Its performance has been so well that it has been one of the dominating algorithms among various types of Kaggle challenges.
XGBoost is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solve many data science problems in a fast and accurate way.
|
|---|
| (source: XGBoost Algorithm) |
As the imgae above summarizes, XGBoost not only provides improvements in terms of the gradient boosting algorithm itself, but also made various improvements related to better hardware utilization, which results in faster processing time. In the following sections, we will talk about the some of the selected improvements suggested in the original XGBoost algorithm.
Regularization
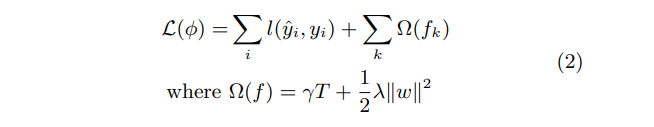
|
|---|
| (source: Original XGBoost Paper) |
Here is the modified / regularized cost function, where the first term is our usual sum of loss functions, but now we also add additional penalties for the following items:
T, which represents the number of trees in the final model, and;|w|, which represents the weights of the leaves in the trees.
Regularization techniques are very common in machine learning models, as it is all too easy to keep adding more parameters to the model without thinking twice, which more often than not leads to overfitting, and this regularization is really nothing new to us if you have followed our Neural Network Series. The gamma and lambda are the regularization weights for the two types of parameters, respectively.
The additional regularization term helps to smooth the final learnt weights to avoid over-fitting. Intuitively, the regularized objective will tend to select a model employing simple and predictive functions. […] When the regularization parameter is set to zero, the objective falls back to the traditional gradient tree boosting.
Second Order Approximation
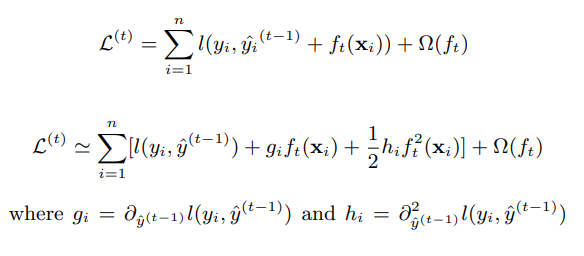
|
|---|
| (source: Original XGBoost Paper) |
Think back on Gradient Boosting, and the cost function described above, together impliy that we will be in pursuit of a new prediction y_hat + f(x), as illustrated in the top equation. To solve this optimization, we employ a second order approximation (think Taylor series), leading us to the bottom equation. Now we will skip a few more steps, but what we wanted to show is that, with this approximation, we were able to efficiently arrive at a numerically accurate solution for the splitting points (new tree structure).
Note that if we recall how we determined the splitting points for Gradient Boosting, it is through usual decision tree fitting. However, when the dataset is very large (VERY large), things could be really slow. Therefore, aside from the “Exact Greedy Algorithm for Split Finding”, the XGBoost author also provided a “Approximate Algorithm for Split Finding” to speed up the algorithm. The actual algorithm is quite involved, but the basic idea is to extract potential splitting points from feature distributions, and assign continuous values into buckets of values that approximate the feature, leading to a largely decreased set of splitting points to search over.
Shrinkage and Column Subsampling
This is a technique we should be familiar from our post on Random Forest and AdaBoosting, where shrinkaga is similar to a learning rate, and Column Subsampling is essentially randomly choosing a subset of features to work with, which further reduces overfitting.
Sparsity-aware Split Finding
When dealing with real-world data, there are often a lot of missing data we need to deal with.
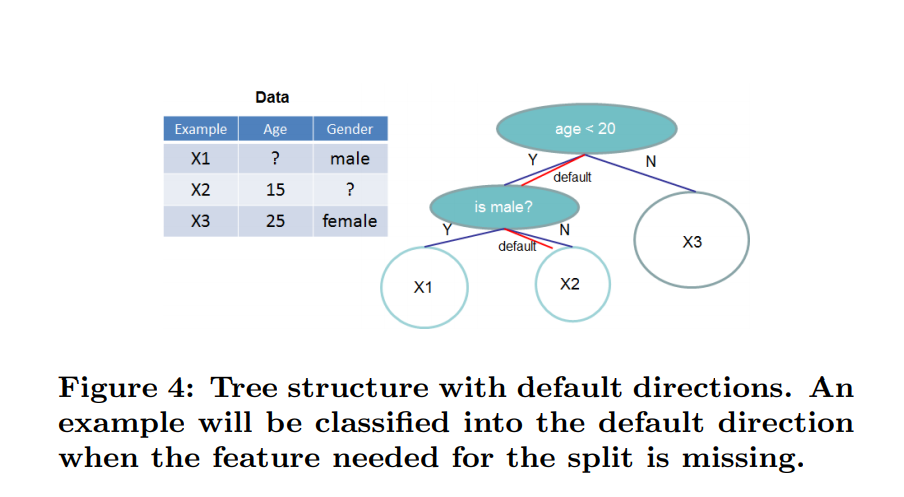
There are multiple possible causes for sparsity: 1) presence of missing values in the data; 2) frequent zero entries in the statistics; and, 3) artifacts of feature engineering such as one-hot encoding. It is important to make the algorithm aware of the sparsity pattern in the data. In order to do so, we propose to add a default direction in each tree node, which is shown in Fig. 4. When a value is missing in the sparse matrix x, the instance is classified into the default direction.
|
|---|
| (source: Original XGBoost Paper) |
XGBoost builds in this functionality to deal with them “optimally”, in the sense that it sets the default direction that results in the lowest lost.
Other Improvements: SYSTEM DESIGN
As mentioned, the author has also proposed a variety of designs that facilitates faster training and processing. We will not go over them in detail here, but just to mention a few:
- “Column Block for Parallel Learning”: Sorting the values is one of the most time-consuming steps in training, and hence, it is proposed to calculate the data once, then store the data in in-memory units, making it available for access in later iterations. However, the access order is not continuous, and hence does not work well with the default cache mechanism.
- Hence, the author proposed “Cache-aware Access”, to “allocate an internal buffer […] fetch the gradient statistics into it”, which in essence is prefetching the required data and optimizes the process.
- “Blocks for Out-of-core Computation”: When the size of data is larger than our memory can hold, it is inevitable that some will have to be held on the disk. However, disk-memory communication is very slow compared to in-memory operations. The authors proposed two solutions: One is Block Compression, which compresses the data, and uses an independent thread to decompress the data on the fly when loading into main memory. The other was called “Block Sharding”, where the data is divided / sharded onto multiple disks, and again uses an independent thread to read the data from multiple sources, and load them into memory buffer.
Conclusion
It is evident from this post that XGBoost was built with very-large data sets in mind - whether it be those approximations, or system designs to speed things up and work with out-of-memory issues, the goal was presumably to be able to scale up to work with Big Data with minimal amount of resources. Now that we have a basic understanding of what XGBoost is and why it just might work, we will work on a Coding example next week to demonstrate the power of XGBoost!

Leave a comment