

Building a Sniping Bot with Python (in the name of automated testing?)
So my brother-in-law has been bugging me lately. To our dismay, he has become a fan of Supreme products. Ever since, he has been complaining how hard it is for anyone to get his or her hands on some of the most coveted items - more often than not, the only way for ordinary people to get them is through reselling sites, at a huge premium.
After a little research, it became obvious that those who are able to get the items upon release, are most likely using bots. What are these so-called bots? It is nothing more than a carefully written script, written to automate and optimize the purchasing process, and to be among the first to get to the checkout line (online). Sounds interesting? Let’s see how we can write up a simple script for exactly that purposes.
This post is purely for educational purposes - please be advised to follow the Terms of Services of each website you visit.
Those paid bots are probably much more sophisticated - this is just an illustration.
What is Selenium?

|
|---|
Selenium is an open-source web-based automation tool often used for automated testing of web applications. It is often paired with Python, since, why not? In some sense, the sniping bot we will be building is also a form of automated testing: Supreme may very well write up the same script, and run it after every new deployment of their web app. If the purchase goes through, awesome, at least the checkout process is not catastrophically buggy! The beauty of such scripts is that you can write them to test all aspects of your web app, and hence whenever you update your codebase, all you need to do is to run the tests and wait for the results, rather than frantically clicking through your web app like a maniac.
Set up
There is little prerequisite here. Aside from pip installing the relevant packages, one extra step is to download and setup the actual driver for your choice of browser. More detailed instructions can be found here. Once you open the link, scroll down to the “Drivers” section, which would walk you through the process. For my example, I will use the Firefox driver.
Goal
For our example, let’s define our goal as follows:
- Given a product name, we search through the listings on
https://www.supremenewyork.com/shopand determine if it exists; - If it does, we navigate to the product detail page, and check if it is available;
- If it is available, add it to our cart;
- Checkout with pre-configured payment information.
- Profit.
To summary: enter a product name, then … profit*!
* Through the mental satisfaction of writing a piece of code that actually runs!
Detailed Steps
0. Laying the Groundwork
from selenium import webdriver
from selenium.webdriver.support.ui import Select
from requests_html import HTMLSession, AsyncHTMLSession
import time
import config
'''
python supreme.py --name="North Face"
'''
base_url = 'https://www.supremenewyork.com'
Here we import the libaries we plan to use, and set the base_url we will be running our script on. config is a local file I use to store some more sensitive info (for example, payment methods), which I can exclude from any versioning software (github). You may have noticed that aside from selenium, I’ve also imported requests_html. This is a more light weight library we can use to do some preliminary probing, when we don’t need to perform too complicated operations. In fact, a separate requests library might be able to cover our preliminary needs, but whatever.
1. Get links to all products
def get_product_links():
'''
Returns list of elements "items",
each containing a link to product detail page
'''
base_shop = base_url + '/shop'
session = HTMLSession()
r = session.get(base_shop)
items = r.html.find('#shop-scroller', first=True).find('li')
return items, session
Here, we build up the url leading to the page that hosts all products, start an HTMLSession, send and process a GET request, which is returned to the variable r. Now we have the html code of the webpage, what next? A common trick is to use the inspection / developer tool on most browsers, either by pressing F12, or right-clicking and select inspect.

|
|---|
For example, here we can see that all the products are wrapped in an ul (unordered list) element, with an id of “shop-scroller”. Within this ul wrapper, each product consists of li (list item) and a nested a tag holding the link to the product details page. Now if we look back onto our code snippet, it looks at the returned r, looks at the html code of it, locates the first (and probably only) element with id of “shop-scroller”, then finds all li elements within.
2. Check for matched product
def get_matched_and_available(target_name):
'''
Given a target name, filter the product on main page,
and return links to products with available items
checked_urls: if already checked (and not a match in product name),
skip in future checks
Exactly how this should work, depends on how the drop works - is the page already there,
just not for sale yet? Or page is added at drop time?
'''
target_name_list = [x.lower() for x in target_name.split(' ')]
potential_urls = []
items, session = get_product_links()
for item in items:
target_url = base_url + item.find('a', first=True).attrs['href']
r = session.get(target_url)
product_name = r.html.find('h2[itemprop=name]', first=True).text.lower()
found = True
for q in target_name_list:
if q not in product_name:
found = False
break
print('**************************')
if found:
print(f'Found a match: {product_name}')
# check if can buy
if check_can_buy(r):
print('Still available.')
potential_urls.append(target_url)
else:
print('No longer available')
else:
print(f'Not a match: {product_name}')
return potential_urls
We first process our input product name (the name we want to match against) into a list of lowercase words. Then we invoke the get_product_links function we’ve defined above, which will hand us over the list of li elements. Now we will loop over the list: for each item in the list, we find the a tag element and access its href attribute. Recall from the screenshot above, that that shall give us the link to the product details page.
Now target_url holds our desired url. We use the same method as above to check out that link:
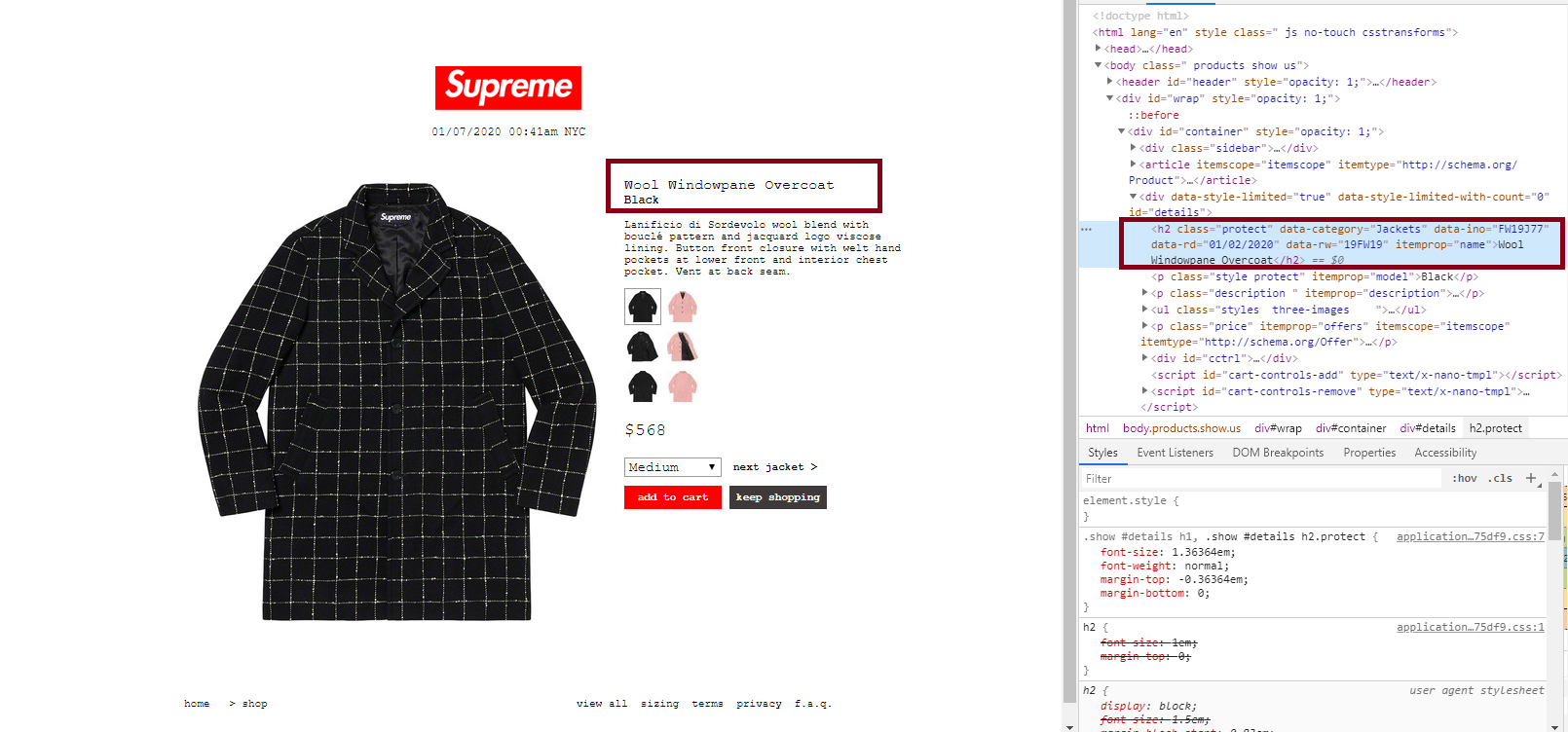
|
|---|
By inspecting the source code, we discovered that the selector h2[itemprop=name] would help us locate the product name. We convert that to lowercase as well, then iterate through our target list: if all words in our search target are contained in the official product name, we say that we have found a match. If a match is found, we will continue go check if it is still available.
3. Check if product available
# check_can_buy invoked above:
def check_can_buy(r):
'''
Given a page (returned by session.get(target_url)),
find if there is such html code within:
<input type="submit" name="commit" value="add to cart" class="button">
Returns True if so, False if not
'''
buy_btn = r.html.find('input[value="add to cart"]', first=True)
return (buy_btn is not None)
Super straightforward - we pass in the same r we have used to figure out the product name, but this time we look for an element with input[value="add to cart"]. We have arrived at this identifier through inspecting various product pages - check out some that are available, some that are sold out, and try to figure out what element’s existence can tell you the product is still available.
4. Perform the purchase
Now that we have got the list of potential_urls returned from step 2 above, we will focus on purchasing whatever product that is on this/these urls.
def perform_purchase(url):
'''
Given url of product, add to cart then checkout
'''
driver = webdriver.Firefox()
# url = "https://www.supremenewyork.com/shop/shirts/p4skltm3i" #a redirect to a login page occurs
driver.get(url)
btn = driver.find_element_by_id('add-remove-buttons').find_elements_by_tag_name('input')
if len(btn) == 0:
print('not available, DONE')
return
btn[0].click()
time.sleep(1)
# go to checkout
checkout_url = 'https://www.supremenewyork.com/checkout'
driver.get(checkout_url)
# fill in form
driver.find_element_by_id('order_billing_name').send_keys(config.NAME)
driver.find_element_by_id('order_email').send_keys(config.EMAIL)
driver.find_element_by_id('order_tel').send_keys(config.PHONE)
driver.find_element_by_id('bo').send_keys(config.ADDRESS)
driver.find_element_by_id('order_billing_zip').send_keys(config.ZIPCODE)
driver.find_element_by_id('order_billing_city').send_keys(config.CITY)
driver.find_element_by_id('rnsnckrn').send_keys(config.CREDIT_CARD)
driver.find_element_by_id('orcer').send_keys(config.CC_CVV)
# driver.find_element_by_id('order_terms').click()
# driver.find_element_by_id('store_address').click()
# remove overlay
ins_tags = driver.find_elements_by_tag_name('ins')
for el in ins_tags:
el.click()
# selections
# driver.find_element_by_id('order_billing_state').send_keys(config.STATE)
# driver.find_element_by_id('credit_card_month').send_keys(config.CC_MONTH)
# driver.find_element_by_id('credit_card_year').send_keys(config.CC_YEAR)
select = Select(driver.find_element_by_id('order_billing_state'))
select.select_by_value(config.STATE)
select = Select(driver.find_element_by_id('credit_card_month'))
select.select_by_value(config.CC_MONTH)
select = Select(driver.find_element_by_id('credit_card_year'))
select.select_by_value(config.CC_YEAR)
time.sleep(2)
# pay
pay_btn = driver.find_element_by_id('pay').find_elements_by_tag_name('input')
pay_btn[0].click()
This step is easier to perform through Selenium, since we will be clicking buttons, and filling out forms, all of which are quite easy with Selenium. The logic is still pretty much the same as using requests_html - we still need to find the elements we are interested in. Here, we first initiate the web driver, navigate to the product details page, and look for an input element within an element with id “add-remove-buttons”. If it’s not there - too bad, we were probably too slow and the product is no longer available.
If it is there, we want to click on it to add to our cart. How do we do it? Well… we simply call the .click() method on the found element. We added a 1 second pause to mimic human behavior - which is probably in vain as we will see later. Now that it is added into our shopping cart, we can navigate to the checkout page. Then we fill in all the info they ask for - again, please be careful with your sensitive info, and only keep it on safe and private locations.
We needed to click on a few checkboxes that are somehow covered by a different element. Selenium conplained, so we had to click on the covering elements instead.
When all info is filled in, we just look for the pay button, and perform another .click(), as simple as that!
Wrapping it Up
For ease of usage, we might want to wrap the codes into a main function, which we could call from outside of Python shell.
def main(target_product):
urls = get_matched_and_available(target_product)
print(f'Found {len(urls)} matches.')
if len(urls) == 0:
print('No match found - checking again')
return
print(f'Processing first url: {urls[0]}')
# just buy the first match
url = urls[0]
perform_purchase(url)
print('Done.')
# define main
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser(description='Supremebot main parser')
parser.add_argument('--name', required=True,
help='Specify product name to find and purchase')
args = parser.parse_args()
main(target_product=args.name)
And to use it, simply run this from command line (where supreme.py is what I named my script):
python supreme.py --name="North Face"
Notes
- If we are actually trying to snipe a product from release, we may want to check availability at a fairly high frequency leading up to the release time, so we can purchase the item as soon as it is released;
- If we actually run the script, we will notice that at the final step, we will be stopped by a reCAPTCHA anti-bot challenge. There are tools to deal with this, but for now, we can solve the challenge manually - still a lot faster than finding the product, adding it to cart, filling in the info, etc. right?

Leave a comment