

XGBoost - Random Forest
Links to Other Parts of Series
Prerequisites
Overview
If you’re not familiar with Decision Trees, and haven’t already checked out the blog post linked above, please check that out first before proceeding with this post on Random Forest, since this does build upon the DT blog post.
Now that we got that covered, let’s dive right in!
What is a Random Forest?
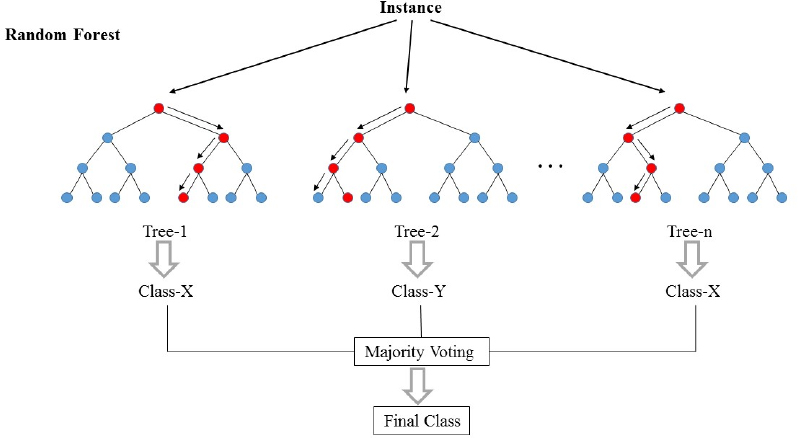
Random Forest is a type of ensemble learning algorithm, which uses and combine multiple variations of similar learning algorithms to produce a potentially better model than any individual algorithms could have produced on its own. Ensembles are used throughout the field, and is by no means anything specific to decision trees. In our Neural Network Series, we have seen that many state-of-the-art results are achieved by ensemble models combining similar models with different configurations. Random Forest is not any different - it builds many Decision Tree models from some sort of random process, then combine the predictive powers of these trees in making a final prediction, usually through a “voting” process ass illustrated below (for classifications), or a simple averaging got regression trees.
|
|---|
| (source: Illustrating the random forest algorithm in TikZ) |
How are DTs constructed?
How do we construct the individual trees that make up our forest? There are usually 2 aspects of randomness involved:
- The sample each tree is trained on is through random selection;
- The set of features each tree considers is also random;
Picking Training Set
This process is commonly referred to as Bagging, or some sort of bootstrapping, whereas for each tree, we will sample, with replacement, a certain amount of data points to make up the training set for this particular decision tree. The effect is that each DT in the forest is effectively trained on a different set of data.
Picking Features
To make the model a Random Forest, we just need to add another layer of randomness: at each split in the learning process, the model selects a random subset of features to use. This is to further remove correlations between trees, which could occur if there is a strong predictor of the target output, so that that feature is selected in all trees. A rule of thumb is to use the square root amount of features at each step for classifications, and one-thrid for regression models, but they should be tuned as a hyper-parameter depending on the specific problems at hand.
Review of Steps
- Decide on the number of trees - typically 500 - 1000 would do;
- For each tree, construct a training set by sub-sampling the whole data set;
- Once the training set is selected, perform the usual DT algorithms with 1 tweak: At each split, choose a random subset of features (ignoring all other data);
- Once we are done with this tree, move on to the next tree and repeat 2 and 3;
- When all trees are done training, the model is ready to be put to use;
- To make a prediction, run the input data through all the trees in the forest. For classifications, take a majority vote and output the most common predicted value. For regression problems, we can take an average.
Bonus: As we’ve mentioned earlier, we can also tune some hyper-parameters such as the number of features we use at each split. To do so, we can use the usual approach of train-validation-test split, and use the validation set to tune our hyper-parameters. Nothing special here!
An Example
Again, scikit-learn is out friend here taking up all the tedious work of implementing the details.
sklearn.ensemble.RandomForestClassifier
A random forest classifier.
A random forest is a meta estimator that fits a number of decision tree classifiers on various sub-samples of the dataset and uses averaging to improve the predictive accuracy and control over-fitting. The sub-sample size is always the same as the original input sample size but the samples are drawn with replacement if bootstrap=True (default).
import pandas as pd
import random
# We again build almost the same dataset as in
# the DecisionTree Example
# But add 2 additional useless features:
# letter_in_name and age, which has the same
# distribution in Male and Female (in our example)
data = []
for i in range(1000):
if random.random() > 0.5:
# generate a male
gender = 'male'
height = 185 + random.randint(-10, 10)
weight = 85 + random.randint(-10, 10)
letters_in_name = random.randint(3, 20)
age = 45 + random.randint(-10, 10)
else:
# generate a female
gender = 'female'
height = 175 + random.randint(-10, 10)
weight = 75 + random.randint(-10, 10)
letters_in_name = random.randint(3, 20)
age = 45 + random.randint(-10, 10)
data.append({
'height': height,
'weight': weight,
'letters_in_name': letters_in_name,
'age': age,
'gender': gender
})
df = pd.DataFrame(data)
# use sklearn's RandomForest Classifier
from sklearn.ensemble import RandomForestClassifier
X = df[['height', 'weight', 'letters_in_name', 'age']]
Y = df['gender']
# specify max depth to 2 as before, but not essential
clf = RandomForestClassifier(max_depth=2)
clf = clf.fit(X, Y)
print(clf.feature_importances_)
# --> [0.57990738 0.40278557 0.00279681 0.01451024]
# yep! features 3 and 4 are indeed identified as quite useless!
Conclusion
We have built on our understanding of Decision Trees, and progressed towards Random Forest models. This indeed helps with out-of-sample predictions as we have discussed in the DT post, but we can make it even better. Next blog post we will talk about AdaBoost, which is another step toward XGBoost (as you can probably tell from its names), and also builds on Random Forest.

Leave a comment